Introduction
Overview
Nuclio is a high-performance "serverless" framework focused on data, I/O, and compute intensive workloads. It is well integrated with popular data science tools, such as Jupyter and Kubeflow; supports a variety of data and streaming sources; and supports execution over CPUs and GPUs. The Nuclio project began in 2017 and is constantly and rapidly evolving; many start-ups and enterprises are now using Nuclio in production.
You can use Nuclio as a standalone Docker container or on top of an existing Kubernetes cluster; see the deployment instructions in the Nuclio documentation. You can also use Nuclio through a fully managed application service (in the cloud or on-prem) in the Iguazio Data Science Platform, which you can try for free.
If you wish to create and manage Nuclio functions through code — for example, from Jupyter Notebook — see the Nuclio Jupyter project, which features a Python package and SDK for creating and deploying Nuclio functions from Jupyter Notebook. Nuclio is also an integral part of the new open-source MLRun library for data science automation and tracking and of the open-source Kubeflow Pipelines framework for building and deploying portable, scalable ML workflows.
Nuclio is extremely fast: a single function instance can process hundreds of thousands of HTTP requests or data records per second. This is 10–100 times faster than some other frameworks. To learn more about how Nuclio works, see the Nuclio architecture documentation, read this review of Nuclio vs. AWS Lambda, or watch the Nuclio serverless and AI webinar. You can find links to additional articles and tutorials on the Nuclio web site.
Nuclio is secure: Nuclio is integrated with Kaniko to allow a secure and production-ready way of building Docker images at run time.
For further questions and support, click to join the Nuclio Slack workspace.
Why another "serverless" project?
None of the existing cloud and open-source serverless solutions addressed all the desired capabilities of a serverless framework:
- Real-time processing with minimal CPU/GPU and I/O overhead and maximum parallelism
- Native integration with a large variety of data sources, triggers, processing models, and ML frameworks
- Stateful functions with data-path acceleration
- Simple debugging, regression testing, and multi-versioned CI/CD pipelines
- Portability across low-power devices, laptops, edge and on-prem clusters, and public clouds
- Open-source but designed for the enterprise (including logging, monitoring, security, and usability)
Nuclio was created to fulfill these requirements. It was intentionally designed as an extendable open-source framework, using a modular and layered approach that supports constant addition of triggers and data sources, with the hope that many will join the effort of developing new modules, developer tools, and platforms for Nuclio.
Quick-start steps
The simplest way to explore Nuclio is to run its graphical user interface (GUI) of the Nuclio dashboard. All you need to run the dashboard is Docker:
docker run -p 8070:8070 -v /var/run/docker.sock:/var/run/docker.sock -v /tmp:/tmp --name nuclio-dashboard quay.io/nuclio/dashboard:stable-amd64
Browse to http://localhost:8070, create a project, and add a function. When run outside of an orchestration platform (for example, Kubernetes or Swarm), the dashboard will simply deploy to the local Docker daemon.
Assuming you are running Nuclio with Docker, as an example, create a project and deploy the pre-existing template "dates (nodejs)".
With docker ps, you should see that the function was deployed in its own container.
You can then invoke your function with curl; (check that the port number is correct by using docker ps or the Nuclio dashboard):
curl -X POST -H "Content-Type: application/text" -d '{"value":2,"unit":"hours"}' http://localhost:37975
For a complete step-by-step guide to using Nuclio over Kubernetes, either with the dashboard UI or the Nuclio command-line interface (nuctl), explore these learning pathways:
- Getting Started with Nuclio on Kubernetes
- Getting Started with Nuclio on Google Kubernetes Engine (GKE)
- Getting Started with Nuclio on Azure Container Service (AKS).
- Hands-on live Kubernetes sandbox and guiding instructions for Nuclio, free on Katacoda
High-level architecture
The following illustrates Nuclio's high-level architecture:
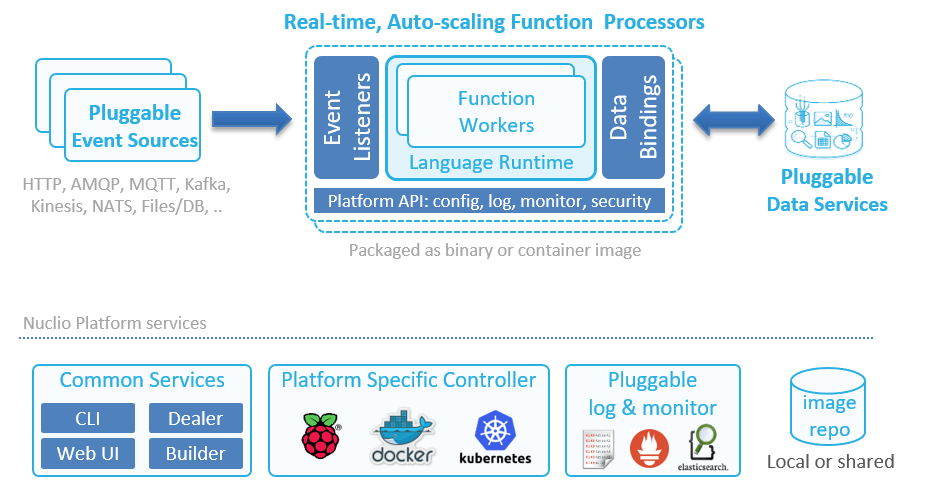
The following is an outline of the main architecture components. For more information about the Nuclio architecture, see Architecture.
Services
Processor
A processor listens on one or more triggers (for example, HTTP, Message Queue, or Stream), and executes user functions with one or more parallel workers.
The workers use language-specific runtimes to execute the function (via native calls, shared memory, or shell). Processors use abstract interfaces to integrate with platform facilities for logging, monitoring and configuration, allowing for greater portability and extensibility (such as logging to a screen, file, or log stream).
Controller
A controller accepts function and event-source specifications, invokes builders and processors through an orchestration platform (such as Kubernetes), and manages function elasticity, life cycle, and versions.
Dashboard
The dashboard is a standalone microservice that is accessed through HTTP and includes a code-editor GUI for editing, deploying, and testing functions. This is the most user-friendly way to work with Nuclio. The dashboard container comes packaged with a version of the Nuclio builder.
Builder
A builder receives raw code and optional build instructions and dependencies, and generates the function artifact — a binary file or a container image that the builder can also push to a specified image repository. The builder can run in the context of the CLI or as a separate service, for automated development pipelines.
Scaler
The scaler is designed to auto-scale, scale-to-zero, and wake up functions, based on the function load and usage.
Function concepts
Triggers
Functions can be invoked through a variety of event sources that are defined in the function (such as HTTP, RabbitMQ, Kafka, Kinesis, NATS, DynamoDB, an Iguazio Data Science Platform stream, or schedule). Event sources are divided into several event classes (req/rep, async, stream, pooling), which define the sources' behavior. Different event sources can plug seamlessly into the same function without sacrificing performance, allowing for portability, code reuse, and flexibility.
SDK
The Nuclio SDK is used by function developers to write, test, and submit their code, without the need for the entire Nuclio source tree.
Function examples
The following sample function implementation uses the Event and Context interfaces to handle inputs and logs, returning a structured HTTP response; (it's also possible to use a simple string as the returned value).
package handler
import (
"github.com/nuclio/nuclio-sdk-go"
)
func Handler(context *nuclio.Context, event nuclio.Event) (interface{}, error) {
context.Logger.Info("Request received: %s", event.GetPath())
return nuclio.Response{
StatusCode: 200,
ContentType: "application/text",
Body: []byte("Response from handler"),
}, nil
}
def handler(context, event):
response_body = f'Got {event.method} to {event.path} with "{event.body}"'
# log with debug severity
context.logger.debug('This is a debug level message')
# just return a response instance
return context.Response(body=response_body,
headers=None,
content_type='text/plain',
status_code=201)
For more examples, see Examples.