kafka-cluster: Kafka Trigger
Overview
The Nuclio Kafka trigger allows users to process messages sent to Kafka. To simplify, you send messages to a Kafka stream (across topics and partitions), tell Nuclio to read from this stream, and your function handler is then called once for every stream message.
In the real world, however, you may want to scale your message processing up and down based on how much the processing occupies your Nuclio function. To support dynamic scaling, several instances ("replicas") of your function must work together to split the stream messages among themselves as fairly as possible without losing any messages and without processing the same message more than once (to the best of their ability).
To this end, Nuclio leverages Kafka consumer groups. When one or more Nuclio replica joins a consumer group, Kafka informs Nuclio which part of the stream it should handle. It does so by using a process known as "rebalancing" to assign each Nuclio replica one or more Kafka partitions to read from and handle; Nuclio's role in the rebalancing process is discussed later in this document (see Rebalancing).
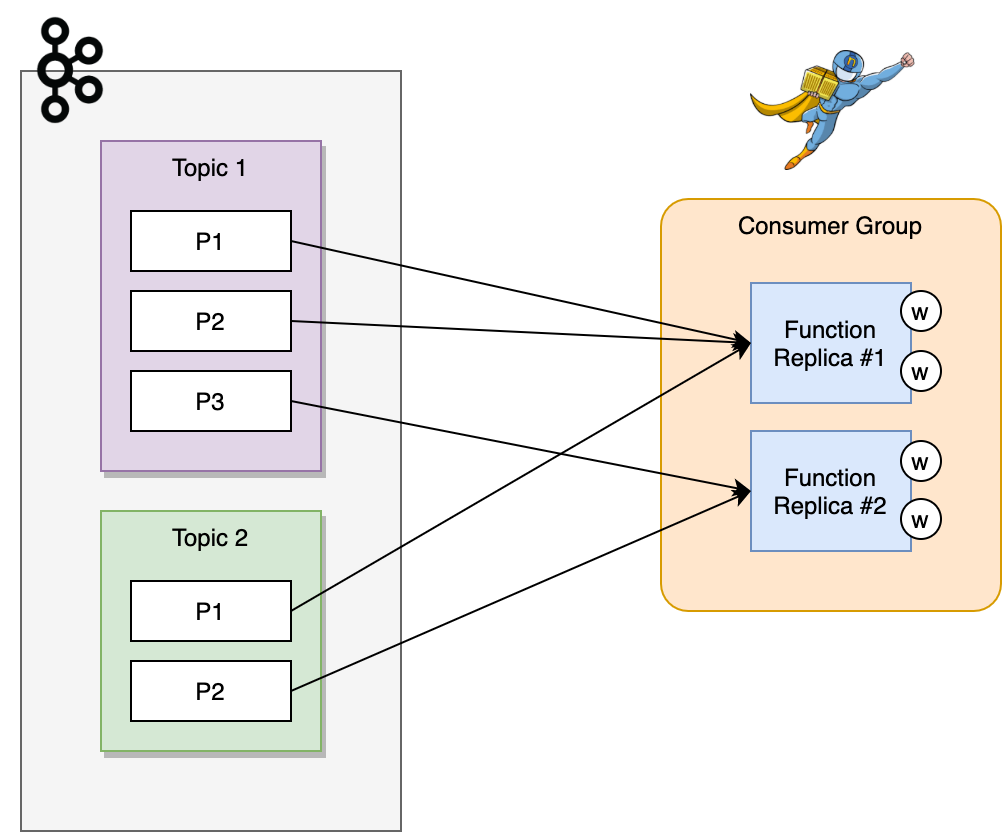
When a Nuclio replica is assigned its set of partitions, it can start using Nuclio workers to read from the partitions and handle them. It's currently guaranteed that a given partition is handled only by one replica and that the messages are processed sequentially; that is, a message will only be read and handled after the handling of the previous message in the partition is completed. During rebalancing, however, the responsibility for a partition may be migrated to another Nuclio replica while still preserving the guarantee of sequential processing (in-order-execution).
Workers and Worker Allocation modes
When a partition is assigned to a replica, the partition messages are handled sequentially by one or more workers; each message is handled by a single worker. You can configure how many workers a single replica contains and how to allocate the workers to process partition messages.
How many workers to allocate for your replica?
Currently, the number of workers for a given replica is statically determined by the user. Fewer workers mean less memory consumption by the replica but a longer wait time before a worker becomes available to process a new message.
A good rule of thumb is to set the number of workers to ceil((<number of partitions> / <max number of replicas>) * 1.2).
For example, if you have 16 partitions and you set the maximum number of replicas to 4, then during steady state each replica handles 16 / 4 = 4 partitions. But if one of the replicas goes down, each replica handles 16 / 3 = 5 or 6 partitions. According to the recommended formula, the maximum number of workers should be ceil((16 / 4) * 1.2) = 5. This means that there's an extra unused worker during steady state, but the message processing won't be stalled significantly if a replica goes down.
How are workers allocated to a partition?
Nuclio supports two modes of worker allocation, which can be configured via the workerAllocationMode configuration parameter:
- Pool mode (
"pool") — In this mode, partitions are allocated to workers dynamically on a first-come, first served basis. Whenever one of the replica's partitions receives a message, the message is allocated to the first available worker. The benefit here is that a worker is never idle while there are messages to process across the replica's partitions. The cost is that messages of a given partition may be handled by different workers (albeit always sequentially). For stateless functions, this is not a problem. However, if your function retains state, you might benefit from "pinning" specific workers to specific partitions by using the"static"allocation mode. - Static mode (
"static") — In this mode, partitions are allocated statically to specific workers; each worker is assigned to handle the messages for specific partitions. For example, if the replica is handling 20 partitions and has 5 workers — partitions 0–3 are handled by worker 0, partitions 3–6 by worker 1, ..., and partitions 16–19 by worker 4. The benefit and cost of this mode are inverse to the"pool"mode: it's entirely possible to encounter stalled processing despite having available workers (because the available workers aren't allocated to the busy partitions), but it's guaranteed that each partition is always handled by the same worker.
Multiple topics
Up until now, the overview discussed partitions and workers. But a Nuclio replica can also read from multiple topics. A Nuclio replica can use its workers to handle the partitions of multiple topics instead of only those of a single topic. For example, if your replica has 10 workers and is configured to handle 10 topics, each with 100 partitions, the replica is essentially using 10 workers to handle 1,000 partitions.
Configuration parameters
Use the following trigger attributes for basic configurations of your Kafka trigger.
You can configure each attribute either in the triggers.<trigger>.attributes.<attribute> function spec element (for example, triggers.myKafkaTrigger.attributes.sessionTimeout) or by setting the matching nuclio.io annotation key (for example, nuclio.io/kafka-session-timeout); (note that not all attributes have matching annotation keys).
For more information on Nuclio function configuration, see the function-configuration reference.
-
topic— The name of the topic on which to listen.
Type:string -
partitions— A list of partitions for which the function receives events.
Type:[]int -
consumerGroup— The name of the Kafka consumer group to use.
Type:string -
initialOffset— The location (offset) within the partition at which to begin the message processing when first reading from a partition. Currently, you can begin the processing either with the earliest or latest ingested messages.
Note that once a partition is read from and connected to a consumer group, subsequent reads are always done from the offset at which the previous read stopped, and theinitialOffsetconfiguration is ignored.
Type:string
Valid Values:"earliest" | "latest"
Default Value:"earliest" -
sasl— A simple authentication and security layer (SASL) object.
Type:objectwith the following attributes -enable(bool) — Enable authentication.user(string) — Username to be used for authentication.password(string) — Password to be used for authentication.
-
sessionTimeout(kafka-session-timeout) — The timeout used to detect consumer failures when using Kafka's group management facility. The consumer sends periodic heartbeats to indicate its liveness to the broker. If no heartbeats are received by the broker before the expiration of this session timeout, the broker removes this consumer from the group and initiates rebalancing. Note that the value must be in the allowable range, as configured in thegroup.min.session.timeout.msandgroup.max.session.timeout.msbroker configuration parameters.
Type:string— a string containing one or more duration strings of the format"[0-9]+[ns|us|ms|s|m|h]"; for example,"300ms"(300 milliseconds) or"2h45m"(2 hours and 45 minutes). See theParseDurationGo function.
Default Value:"10s"(10 seconds) -
heartbeatInterval(kafka-heartbeat-interval) — The expected time between heartbeats to the consumer coordinator when using Kafka's group management facilities. Heartbeats are used to ensure that the consumer's session stays active and to facilitate rebalancing when new consumers join or leave the group. The value must be set lower than thesessionTimeoutconfiguration, but typically should be set no higher than 1/3 of that value. It can be adjusted even lower to control the expected time for normal rebalancing.
Type:string— a string containing one or more duration strings of the format"[0-9]+[ns|us|ms|s|m|h]"; for example,"300ms"(300 milliseconds) or"2h45m"(2 hours and 45 minutes). See theParseDurationGo function.
Default Value:"3s"(3 seconds) -
workerAllocationMode(kafka-worker-allocation-mode) — The worker allocation mode.
Type:string
Valid Values:"pool" | "static"
Default Value:"pool"
How a message travels through Nuclio to the handler
Nuclio leverages the Sarama Go client library (sarama) to read from Kafka. This library takes care of reading messages from Kafka partitions and distributing them to a consumer — in this case, the Nuclio trigger. A Nuclio replica has exactly one instance of Sarama and one instance of the Nuclio trigger for each Kafka trigger configured for the Nuclio function.
Upon its creation, the Nuclio trigger configures Sarama to start reading messages from a given broker, topics, or consumer group. At this point, Sarama calculates which partitions the Nuclio replica must handle, communicates the results to the Nuclio trigger, and then starts dispatching messages.
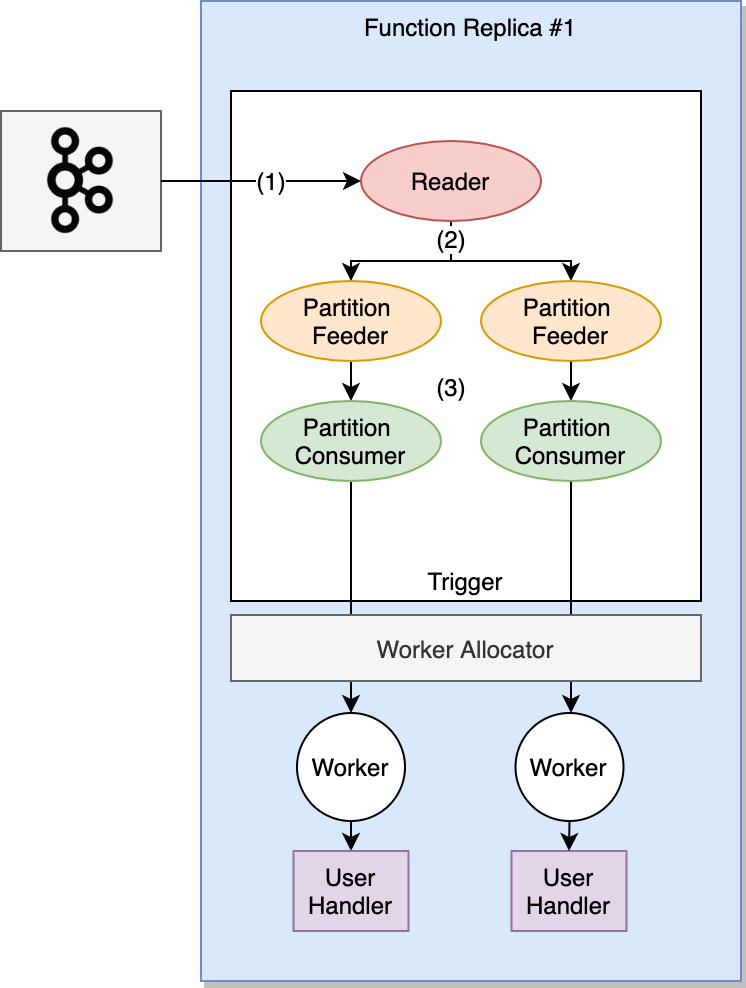
As the first step, Sarama reads a chunk of data from all partitions that are assigned to it, across all topics (1). The amount of data to read per partition is determined in bytes and controlled by the function configuration. Ideally, each read returns data across all partitions, but this is highly dependant on the configuration and the size of messages in the partitions (see the following explanation).
When Kafka responds with a set of messages (per topic or partition), Sarama sends this information to all of its partition feeders through a queue (2). The size of this queue is exactly one and is not configurable. The partition feeder (which is running in a separate "thread") reads the response and plucks and parses the relevant messages for the topic or partition that it's handling. For each parsed message, the feeder writes the processed data to the partition consumer queue (3); the size of this queue is determined by the channelBufferSize configuration . If there's no space in the queue, Sarama waits approximately for the duration of the maxProcessingTime configuration before giving up and killing the child. This partition consumer queue allows Sarama to queue messages from Kafka so that the partition consumer never waits for reads from Kafka.
A large partition consumer queue reduces processing delays (as there are almost always messages waiting in the queue to be processed), but it costs memory and the processing time that's required to read the data from Kafka if the replica goes down.
The Nuclio trigger reads directly from this partition consumer queue (remember that there's one such message queue per partition), and for each message it allocates a worker and sends the message to be handled. When the handler returns, a new message is read from the queue and handled.
Configuration parameters
Use the following trigger attributes for message-course trigger configurations.
You can configure each attribute either in the triggers.<trigger>.attributes.<attribute> function spec element (for example, triggers.myKafkaTrigger.attributes.fetchMin) or by setting the matching nuclio.io annotation key (for example, nuclio.io/kafka-fetch-min).
-
fetchMin(kafka-fetch-min) — The minimum number of message bytes to fetch in a request (similar to the JVM'sfetch.min.bytesconfiguration). If insufficient data is available, the broker waits for this amount of bytes to accumulate before answering the request. The default setting of 1 byte means that fetch requests are answered as soon as a single byte of data is available or the fetch request times out waiting for data to arrive. A value of 0 causes the consumer to spin when no messages are available. A value greater than 1 causes the server to wait for larger amounts of data to accumulate, which can improve server throughput a bit at the cost of some additional latency.
Type:int
Valid Values:[0,...]
Default Value:1 -
fetchDefault(kafka-fetch-default) — The default number of message bytes to fetch from the broker in each request. This value should be larger than the majority of your messages, otherwise the consumer will spend a lot of time negotiating sizes and not actually consuming.
Type:int
Valid Values:[0,...]
Default Value:1048576(1 MB) -
fetchMax(kafka-fetch-max) — The maximum number of message bytes to fetch from the broker in a single request (similar to the JVM'sfetch.message.max.bytesconfiguration). Messages larger than this value returnErrMessageTooLargeand are not consumable, so ensure that the value is at least as large as the size of the largest message. Note that the globalsarama.MaxResponseSizeconfiguration still applies.
Type:int
Valid Values:[0,...]
Default Value:0(no limit) -
channelBufferSize(kafka-channel-buffer-size) — The number of events to buffer in internal and external channels. This permits the producer and consumer to continue processing some messages in the background while user code is working, thus greatly improving throughput.
Type:int
Valid Values:[1..256]or0to apply the default value
Default Value:256 -
maxProcessingTime(kafka-max-processing-time) — The maximum amount of time that the consumer expects a message takes to process for the user. If writing to the Messages channel takes longer, the partition stops fetching messages until it can proceed.
Note that, since the Messages channel is buffered, the actual grace time ismaxProcessingTime *channelBufferSize.
If a message is not written to the Messages channel between two ticks of the Sarama ticker (expiryTicker), a timeout is detected. Using a ticker instead of a timer to detect timeouts should typically result in much fewer calls to Timer functions, which may result in a significant performance improvement if many messages are being sent and timeouts are infrequent. The disadvantage of using a ticker instead of a timer is that timeouts are less accurate. That is, the effective timeout could be betweenMaxProcessingTimeand2 * MaxProcessingTime. For example, ifMaxProcessingTimeis 100 ms, then a delay of 180 ms between two messages being sent may not be recognized as a timeout.
Type:string— a string containing one or more duration strings of the format"[0-9]+[ns|us|ms|s|m|h]"; for example,"300ms"(300 milliseconds) or"2h45m"(2 hours and 45 minutes). See theParseDurationGo function.
Default Value:"5m"(5 minutes)
Offset management
Nuclio replicas can come up and go down on a whim (mostly due to auto-scaling), and the responsibility for a given partition migrates from one replica to the other. It's important to ensure that the new replica picks up where the previous replica left off (to avoid losing or re-processing messages). Kafka offers a persistent "offset" per partition, which indicates the consumer group's location in the partition. New Nuclio replicas can read this offset and start reading the partition from the relevant location.
However, the Nuclio replica is responsible for updating this offset. Naively, whenever a message is handled, Nuclio can contact Kafka and tell it to increment the offset of the partition. This would carry a large overhead per message and therefore be very slow.
The Sarama library offers an "auto-commit" feature wherein Nuclio replicas need only "mark" the message as handled to trigger Sarama to update Kafka periodically, in the background, about the current offsets of all partitions. The default interval is one second and cannot be configured at this time.
In addition to periodically committing offsets, Nuclio and Sarama "flush" the marked offsets to Kafka whenever a replica stops handling a partition, either because of a rebalancing process or some other condition that caused a graceful shutdown of the replica.
Rebalancing
A rebalance process ("rebalancing") is triggered whenever there's a change in the number of consumer group members. This can happen in the following situations:
- The Nuclio function comes up and all Nuclio replicas are spawned. (Note that because replicas don't come up at the same time, several rebalancing processes may initially occur.)
- A new Nuclio replica joins as a result of an auto-scaling spin-up.
- A Nuclio replica goes down as a result of a failure or an auto-scaling spin-down.
When Kafka detects a change in members, it first instructs all existing members to stop their processing and "return" their partitions. When the membership stabilizes, Kafka splits the partitions across all existing members (Nuclio replicas), and each replica can then start the previously described consumption process.
This process is handled by Sarama but requires very careful logic on the Nuclio end, because Sarama is very strict with regard to time lines in this context. For example, the Nuclio partition consumer must finish handling messages well before the rebalancing timeout period (rebalanceTimeout) elapses, because Sarama needs to do clean-up of its own.
However, Nuclio might be busy waiting for the user's code to finish processing an event, which can take an undetermined amount of time that's out of Nuclio's control. When the rebalanceTimeout period elapses, Sarama exits the membership and may return only when the messages stored in the partition consumer queue are handled. This is very problematic because when this happens, it triggers another rebalancing process (a member leaving the group), which might cause this condition on another replica.
To prevent this, Nuclio has a hard limit on how long it waits for handlers to complete processing the event (maxWaitHandlerDuringRebalance). If rebalancing occurs while a handler is still processing an event, Nuclio waits for a duration of maxWaitHandlerDuringRebalance before forcefully restarting the worker (in runtimes that support this, such as Python) or the replica (in runtimes that don't support worker restart, such as Golang).
This aggressive termination helps the consumer groups stabilize in a deterministic time frame, at the expense of re-processing the message. To reduce this occurrence, consider setting a high value for the rebalanceTimeout and maxWaitHandlerDuringRebalance configurations.
- Rebalancing configuration parameters
- Choosing the right configuration for rebalancing
- Rebalancing notes
Configuration parameters
Use the following trigger attributes for rebalancing trigger configurations.
You can configure each attribute either in the triggers.<trigger>.attributes.<attribute> function spec element (for example, triggers.myKafkaTrigger.attributes.rebalanceTimeout) or by setting the matching nuclio.io annotation key (for example, nuclio.io/kafka-rebalance-timeout).
-
rebalanceTimeout(kafka-rebalance-timeout) — The maximum allowed time for each worker to join the group after rebalancing starts. This is basically a limit on the amount of time needed for all tasks to flush any pending data and commit offsets. If this timeout is exceeded, the worker is removed from the group, which results in offset commit failures.
Type:string— a string containing one or more duration strings of the format"[0-9]+[ns|us|ms|s|m|h]"; for example,"300ms"(300 milliseconds) or"2h45m"(2 hours and 45 minutes). See theParseDurationGo function.
Default Value:"60s"(60 seconds) -
rebalanceRetryMax(kafka-rebalance-retry-max) — When a new consumer joins a consumer group, the set of consumers attempt to "rebalance" the load to assign partitions to each consumer. If the set of consumers changes during this assignment, the rebalancing fails and is then retried. This configuration controls the maximum number of retry attempts before giving up.
Type:int
Default Value:4 -
rebalanceRetryBackoff(kafka-rebalance-retry-backoff) — Back-off time between retries during rebalancing.
Type:string— a string containing one or more duration strings of the format"[0-9]+[ns|us|ms|s|m|h]"; for example,"300ms"(300 milliseconds) or"2h45m"(2 hours and 45 minutes). See theParseDurationGo function.
Default Value:"2s"(2 seconds) -
maxWaitHandlerDuringRebalance(kafka-max-wait-handler-during-rebalance) — The amount of time to wait for a handler to return when a rebalancing occurs before restarting the worker or replica.
Type:string— a string containing one or more duration strings of the format"[0-9]+[ns|us|ms|s|m|h]"; for example,"300ms"(300 milliseconds) or"2h45m"(2 hours and 45 minutes). See theParseDurationGo function.
Default Value:"5s"(5 seconds)
Choosing the right configuration for rebalancing
In a perfect world, Nuclio would be configured out of the box to perform in the most optimal way across all use cases. In fact, if your worst-case event-processing time is short (a few seconds), then Nuclio does just that: you can leave the default configurations as-is and Nuclio should perform optimally under normal network conditions. However, if your worst-case event-processing time is in the order of tens of seconds or minutes, you must choose between the following configuration alternatives:
Prioritizing throughput (default)
During rebalancing, replicas stop processing while the new generation of the consumer group stabilizes and all members are allocated partitions. This means that while rebalancing is taking place, messages from Kafka aren't processed, which reduces the average pipeline throughput. Ideally, once a rebalancing process is initiated (for any of the reasons previously explained), all replicas immediately stop their current processing and join the rebalancing process. However, if there's a long event processing in progress, the workers processing the event can only join the rebalancing process after the current event processing completes and the user handler that received the event returns, which might take a while.
To join the rebalancing process as quickly as possible, you need to stop processing the event immediately or after a short deterministic grace periodic. Obviously, in this scenario Nuclio would not mark the event as processed because it didn't complete the processing, and therefore the event will be processed again by the replica that's assigned this partition in the new consumer-group generation.
To configure this processing logic, set maxWaitHandlerDuringRebalance to a short time period, like 5 or 10 seconds. Nuclio will only wait this short amount of time before stopping the event processing and joining the rebalancing process, resulting in duplicate event processing in favor of a higher throughput.
Prioritizing minimum duplicates
There are many scenarios in which you might prefer to instruct Nuclio to wait for the completion of all active event processing before joining a rebalancing process — for example, when duplicate processing incurs a high cost. This means blocking the rebalancing process and effectively halting all new event processing until the current event processing is done.
To configure this processing logic, set maxWaitHandlerDuringRebalance to your worst-case event-processing time, and set rebalanceTimeout to approximately 120% of maxWaitHandlerDuringRebalance. For example, if your worst-case event-processing time is 4 minutes, set maxWaitHandlerDuringRebalance to 4 minutes and rebalanceTimeout to 5 minutes. Increasing the rebalancing timeout guarantees that the replica or replicas that are waiting for 4 minutes (or less) for the event processing to complete are guaranteed not to be removed from the consumer group for 5 minutes, thus avoiding another rebalancing process that would be triggered if the member replica left the group.
Rebalancing notes
Note that Nuclio's Kafka client, Sarama, performs pre-fetching of channelBufferSize messages from Kafka into the partition consumer queue. It does so to reduce the number of times it needs to contact Kafka for messages, and to allow workers to (almost) always have a set of messages waiting to be processed without having to wait a round-trip time for Kafka to fetch the messages. During rebalancing, regardless of whether you prefer a higher throughput or minimum duplicates, the messages in this queue are discarded and have no effect on the rebalancing time. (I.e., it doesn't matter if you have one message in the queue or 256; all messages are discarded and re-fetched by the replica that handles this partition in the new consumer-group generation.)
Configuration example
triggers:
myKafkaTrigger:
kind: kafka-cluster
attributes:
initialOffset: earliest
topics:
- mytopic
brokers:
- 10.0.0.2:9092
consumerGroup: my-consumer-group
sasl:
enable: true
user: "nuclio"
password: "s3rv3rl3ss"